
AI‑Assisted Software Engineering: Creating Complex Projects from Scratch. TDD and Spec-First Approaches
In my previous article I’ve shown how to create a single component with AI coding agents supporting Plan Mode.
Here we’ll go further and will develop a real multi-component application with non-trivial logic, db, frontend etc.
This time we’ll use Claude Code, but I will on purpose use almost none of the Claude Code advanced features like skills, custom sub-agents and official or community plugins for the following reasons:
- Coding agents’ harnesses (Cursor, Claude Code, Codex, etc.) change all the time and will be very different next year, but the core principles will stay the same.
- Ready-to-use third-party bundles (plugins) for complex development are complicated and don’t give you full control over context and development flow. They are great instruments, but during early adoption of AI coding agents in your work it’s better to have full control of the process. For the same reason why back in the day it was preferable to study software development in languages like C/C++, and only then start using heavy platforms like Java and .NET.
The only exception to the above principle is the usage of context7 MCP server, that provides the agent with up-to-date documentation on usage of libraries and instruments (Docker, databases, etc).
The application used as an example in this article can be found in this repository. This is a web application for creating recipes and calculating nutrition facts. The stack is: React SPA, Python backend, PostgreSQL, nginx, Docker. The exact logic and technology stack doesn’t matter and I won’t focus on this: it can be anything else.
1. Approach
When developing complex applications there are four main pillars on which the entire process will be based:
- Initial human-written specification describing two distinct things:
- Required business logic and functionality
- Technical requirements, highlighting core technical decisions made by the human responsible for technical implementation of the app. It should not be deep in all directions: the developer should clearly communicate aspects of technical implementation that are important for them and also state what decisions the agent should make independently.
It may be one single textual document describing both these aspects or two different documents prepared by two different persons (e.g. Product Manager and Technical Leader).
- Multi-phase development flow. During initial planning the AI coding agent is instructed to plan implementation of the entire system as a series of separate phases. Each phase will then be implemented in a separate session, so the entire context window will be dedicated to this phase only.
- TDD: The AI coding agent is instructed to create tests (integration and/or unit) that will serve as part of the definition of done for each phase. Creation of tests is done in a session separate from the functionality implementation itself.
- Regular check if the code drifts from the plan. On every new session, the agent is instructed to double-check if the existing implementation plan is consistent with the existing plan and change the code or plan itself if it does not affect the overall requirements.
In the following sections we’ll see all these principles in action.
2. Development Flow
Enough said, let’s start development.
2.1. Step 1: Initial Planning
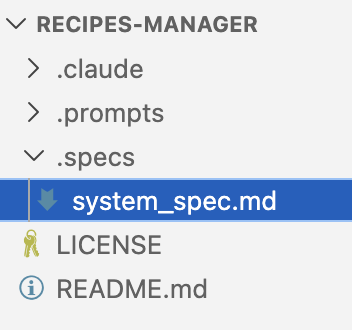
So, your business and technical requirements are written. In my example, I’ve put them all in a single document system_spec.md file that is the only thing I have in the repo for now:
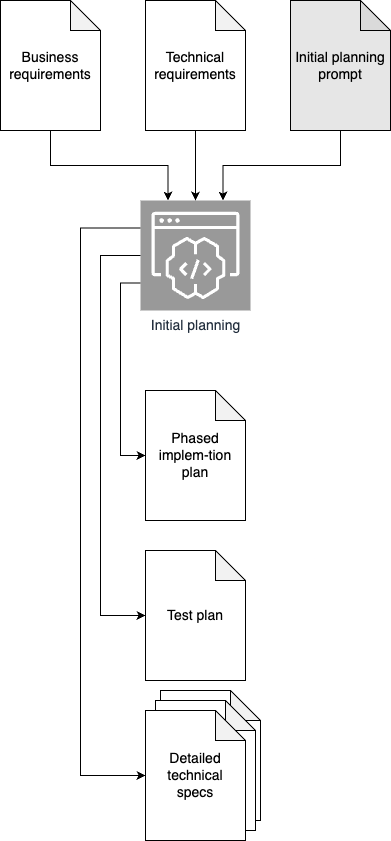
Our goal is to convert it to the following set of AI-generated documents:
- Detailed implementation plan split into sections
- Test plan, containing descriptions of tests required to verify each phase
- A set of super detailed specification files. The exact set of files will depend on the project. In my example they are:
- REST API specification describing all the endpoints
- DB schema description
Graphically this step may be depicted as follows:
The planning prompt should provide a specific description of what you want to get. The one I’ve used in this project can be seen on GitHub. Here I provide its trimmed version:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
Read `.specs/system_spec.md` and `CLAUDE.md`.
This is an empty repo. I need you to produce the planning artifacts for
this project. Do not write any implementation code.
Deliverables:
1. `.specs/ai_gen/api_spec.md` — complete REST API specification
<trimmed>
2. `.specs/ai_gen/db_schema.md` — complete Postgres schema
<trimmed>
3. `.specs/ai_gen/implementation_plan.md` — phased implementation plan
<trimmed>
4. `.specs/ai_gen/testing_strategy.md` — testing approach
<trimmed>
5. Updated `CLAUDE.md`
<trimmed>
Use context7 MCP whenever you need current library docs (FastAPI, SQLAlchemy
async, pyjwt, Zalando guidelines, chosen frontend framework, pytest, etc).
Before writing anything, explore the spec carefully and ask me clarifying
questions about anything ambiguous or underspecified. I'd rather resolve
ambiguity now than discover it mid-implementation.
📝 Specifically in Claude Code I recommend to create CLAUDE.md based on business and technical requirements. I’ve used this prompt to do it. The /init command won’t give you good result, because our repo is almost empty.
Now all we need to do is to open Claude Code, switch to Plan mode and paste this prompt. You will be asked follow-up questions and, once the plan is executed, you’ll end up with all you need to start actual development:
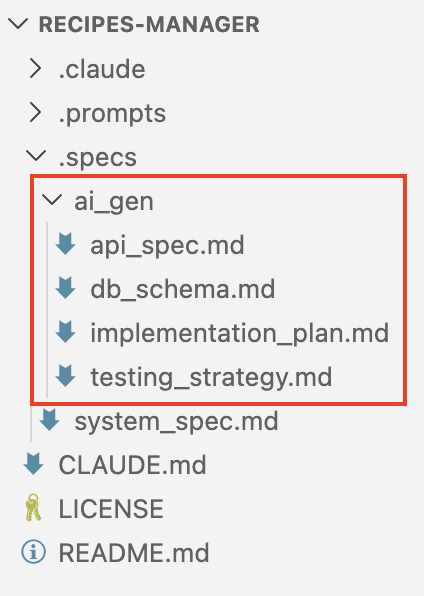
This is what I’ve got: GitHub.
2.1.1. Pro Tips for Initial Planning and Technical Requirements
Use context7
context7 is a service providing MCP access to up-to-date documentation on almost every existing library and tool. I refer to it in prompts regularly, for example:
1
2
Use context7 MCP whenever you need current library docs (FastAPI, SQLAlchemy
async, pyjwt, Zalando guidelines, chosen frontend framework, pytest, etc).
Vary the depth of technical requirements
You almost never need technical requirements that are deep and detailed in every aspect. For example, in my system_spec.md file I’m very detailed about code structure, core abstractions and architecture. But since I don’t care much about the frontend part, the only thing I’ve provided about it is:
1
2
3
## 4.1. Frontend App
Choose the framework yourself. It should be something simple and reliable. Code should be organized according to best practices for this framework.
The web app should work and be automatically adjustable for both regular screens and mobile.
Essentially, I’ve just delegated the frontend part to an AI agent entirely.
Use integration tests for containerizable components
In cases when you don’t really need unit tests of super critical classes / functions, you may ask the agent to make integration tests for containerizable components of the system. For example, this is the part of initial planning prompt, where I describe this testing infrastructure:
1
2
3
4
5
6
7
8
9
10
11
4. `.specs/ai_gen/testing_strategy.md` — testing approach
- For the sake of simplicity, only integration tests should be implemented, **not** unit tests of separate classes/functions.
- Tests for each phase of development (see point 3) should be implemented in the `tests` folder. Subfolder for each phase should be called using template `phase-{phase_num}-{phase_name}`
- Tests should be written in Python using the `pytest` framework
- For tests you must create custom `docker-compose.yml` files inside test folders. If you need some test-specific configuration of the environment - do it there. For example, for testing the REST API you can create a `docker-compose.yml` with the backend app bound to the host's port (this won't be the case for the final deliverable).
- Tests-specific `docker-compose.yml` files must be completely independent from the root-level `docker-compose.yml`.
- Never bind Docker ports to port 80 of the host. Use configurable (8080 by default) host port for exposing nginx
- Tests for infrastructure, backend and db phases should only verify things testable via network connection. For example you can test api endpoints, healthchecks, connect to db (exposed in test-specific `docker-compose.yml`) to verify schema, etc. But you should never try to create tests requiring anything beyond a network connection to the component you're testing (e.g. manipulation of files on the host machine).
- For tests of frontend phases and final phase (integration and consolidation) you must use `pytest-playwright` to test the system e2e, mimicking a real user using the app via the frontend.
- Tests should be independent of each other and runnable one by one in any order
- When development is done, a single script to run all the tests should be created. All information required for running tests by agents should be added to `CLAUDE.md`
Use the most advanced model with max reasoning
Initial planning is the most reasoning-heavy part of the flow, so it’s better to use the best available model during it. High-quality output of the planning will allow you to get good results with a cheaper model during development.
2.2. Step 2: Read AI-generated Specifications!
Ok, now is the most exhausting part.
You need to actually verify the output generated in Step 1, and fix if needed. Of course you can easily skip it if this is your pet project, but if this is a commercial product I would recommend you actually check it. It will save you time in the future.
2.3. Step 3: Iterative Implementation of Tests and Code
Now the easy part: implement software based on the implementation plan generated by the agent. Each of the two steps provided below should be repeated for each phase from the AI-generated implementation plan. Both of them should be done in Plan mode in separate sessions.
☝️ Note how the prompts below instruct the coding agent to check the specification and (if shifts detected) to ask the developer if the specification should be fixed to make it consistent with reality. This regular sanity check on each step of development helps to keep the context consistent and reduce the risk of confusing the LLM with contradictory requirements.
2.3.1. Prompt for Generating Tests for Phase N
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
Our goal is to create integration tests for Phase {N} from `.specs/ai_gen/implementation_plan.md` according to `.specs/ai_gen/testing_strategy.md`. Passing these tests will serve as part of the definition of done for the implementation of this phase, which will be done in a separate session.
Tests won't be changed during the implementation of the phase.
Before planning:
- Read `CLAUDE.md`, `.specs/system_spec.md`, `.specs/ai_gen/api_spec.md`, `.specs/ai_gen/db_schema.md`, `.specs/ai_gen/testing_strategy.md`, and `.specs/ai_gen/implementation_plan.md`.
- Explore the current state of the repo.
During planning:
1. Confirm the planned approach in `.specs/ai_gen/implementation_plan.md` and `.specs/ai_gen/testing_strategy.md` are still fits the current codebase. Flag any divergences between the plan and reality. If any, confirm them with the user during planning using `AskUserQuestion` tool and update `.specs/ai_gen/*.md` / `CLAUDE.md` to make it consistent with reality.
2. Flag any ambiguities, missing details, or decisions that need to be made before test implementation starts.
3. List the concrete files you will create or modify.
4. List the test deliverables for this phase from the plan and testing strategy and decide on how you'll implement them.
5. Use context7 for any library docs you need.
Final deliverable should be tests in a separate subfolder of the `tests` directory, created according to `.specs/ai_gen/testing_strategy.md`. These tests should fail because the functionality for this phase is yet to be implemented.
After implementation is complete:
- Review `.gitignore` and add any entries needed to exclude files that should not be version-controlled, based on the languages, frameworks, tools, and build artifacts actually introduced or used in this session (e.g., language-specific caches, dependency directories, build outputs, virtual environments, IDE/editor metadata, OS-generated files, local environment files, test/coverage artifacts). Only add entries that are actually relevant to this repo's stack - do not paste in generic boilerplate. Preserve existing entries; do not remove or reorder them. If `.gitignore` does not exist, create it.
- [Optional] Make all the required changes in `.specs/ai_gen/*.md` files if during planning you've found any divergences between the plan and current state of the codebase and the user confirmed the changes. These changes must be as pointed as possible and always must be confirmed by the user.
2.3.2. Prompt for Implementation of Phase N
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
Our goal is to implement Phase {N} from `.specs/implementation_plan.md`. The integration tests for this phase already exist under `tests/` (created in a previous session) and must not be modified, skipped, or deleted. Passing all of these tests — and not regressing any tests from earlier phases — is an essential part of the definition of done for this phase. No additional tests (unit tests, extra integration tests, smoke tests, etc.) should be created.
Before planning:
- Read `CLAUDE.md`, `.specs/system_spec.md`, `.specs/ai_gen/api_spec.md`, `.specs/ai_gen/db_schema.md`, `.specs/ai_gen/testing_strategy.md`, and `.specs/ai_gen/implementation_plan.md`.
- Locate and read the existing integration tests for Phase {N} under `tests/`.
- Explore the current state of the repo, including any code from earlier phases this phase builds on.
During planning:
1. Confirm the planned approach in `.specs/ai_gen/implementation_plan.md` still fits the current codebase. Flag any divergences between the plan and reality. If any, confirm them with the user during planning using `AskUserQuestion` tool and update `.specs/ai_gen/implementation_plan.md` / `CLAUDE.md` to make it consistent with reality.
2. Confirm the existing Phase {N} integration tests are consistent with the plan and the specs. Flag any contradictions, gaps, or tests that appear to encode requirements not present in the specs. Surface these to the user before proceeding — do not modify the tests unilaterally.
3. Flag any ambiguities, missing details, or decisions that need to be made before implementation starts.
4. List the concrete files you will create or modify.
5. List the implementation deliverables for this phase from the plan and map each one to the tests it must satisfy. Identify any deliverable that is not currently covered by a test and surface it to the user.
6. Use context7 for any library docs you need.
Final deliverable should be a working implementation of Phase {N} such that:
- All existing Phase {N} integration tests pass.
- All tests from earlier phases continue to pass (no regressions).
- No existing tests are modified, skipped, or deleted.
- No new tests are added.
- The code conforms to `CLAUDE.md` and phase specification.
After implementation is complete:
- Review `.gitignore` and add any entries needed to exclude files that should not be version-controlled, based on the languages, frameworks, tools, and build artifacts actually introduced or used in this session (e.g., language-specific caches, dependency directories, build outputs, virtual environments, IDE/editor metadata, OS-generated files, local environment files, test/coverage artifacts). Only add entries that are actually relevant to this repo's stack - do not paste in generic boilerplate. Preserve existing entries; do not remove or reorder them. If `.gitignore` does not exist, create it.
- [Optional] Make all the required changes in `.specs/ai_gen/*.md` files if during planning you've found any divergences between the plan and current state of the codebase and the user confirmed the changes. These changes must be as pointed as possible and always must be confirmed by the user.
3. Conclusion
This approach is a good starting point for creating your own AI-assisted development flow tailor-made for your needs. It doesn’t guarantee bug-free software, but it successfully mitigates many drawbacks of LLMs, by constructing rich context, keeping it consistent and providing strict guardrails (specs and tests) to minimize hallucinations.
And of course, due to the deterministic nature of this workflow, it is automatable. But this is the topic for another text.